Bring Back the Basics-A deeper Dive to Practical Field Instrumentation in Process Safety Service (Part 2)
Bring Back the Basics-A deeper Dive to Practical Field Instrumentation in Process Safety Service (Part 2)
Bring Back the Basics – A deeper Dive into Practical Field Instrumentation in Process Safety Service
(Blog Series Part 2)
General Requirements

When it comes to specification of field instrumentation used for Process Safety related applications, designers are often left on their own to specify the instrumentation. SIF input and output performance may be specified in a Safety Requirements Specification, but all too often I’ve observed that these specifications are minimal or go directly to specifying a manufacturer and model number without defining what the performance requirements actually are. I’ve also observed some level of carelessness in specifying field instrumentation for Process Safety related applications. Engineers, being Engineers are often attracted to shiny things. This doesn’t really have a role in selecting field instruments for Safety Related Services. I’ve seen quite a few instances where inappropriate selections were made in pursuit of the bright and shiny.
Field instrumentation must be specified and installed so that it meets the requirements of the IPL or the SIF Safety Requirements Specification. Some of the considerations to include when selecting the field instrumentation and its installation are:
- Ability to make the required measurements with the required accuracy and response time
- Independence of the measurement from IPL Initiating Causes and from other IPL’s
- Ability of final elements to execute the required Safe State actions with the required response time and performance
- Availability of the instruments and the ability to deliver performance that meets the IPL or SRS Integrity Level requirements
- Reliability of the instruments and their installation to deliver the SIF Spurious Trip Rate specified in the SRS.
- Maintainability and Testability of the instruments
Making the Measurement
Quality input measurements are critical to a SIF’s or other instrumented IFPL’s successful implementation. Selection of input field instruments must be reliable and provide the level of accuracy of the measurements needed to provide a well performing IPL or SIF.
Input measurement instruments should be selected based upon a User Organization’s experience with the measurement methods and the devices specified. They also only need to perform well enough to meet the requirements. Over specifying accuracy or attempting to use measurement methods that don’t have an established track record can result in poor IPL performance. This isn’t always obvious to a lot of SIS engineers or to the engineers specifying the field instrumentation. Specification of new, untried measurement techniques has gotten more than one engineer in trouble in the pursuit the new, bright and shiny. A few applications where this has resulted in problems are highlighted below
- A Site was moving towards greater use of guided wave radar level measurements. Early experience in a few test applications had been limited, but positive. A decision was made to apply them to a retrofit of a set of reciprocating compressor protective shutdowns. The designs proved to be unreliable for shutdown applications as the measurements would frequently drop out for short periods, but which the shutdown systems saw and shut down the compressors repeatedly. Since then, guided wave instrument manufacturers have refined their designs to address the problems that were causing the instrument signals to drop out.
- A Site was moving towards the use of vortex shedding flow meters as an alternative to traditional orifice plate and DP transmitter flow measurements. A decision was made to apply them to a process heater low feed shutdown. Further, to save the cost of multiple flow meters a two-head vortex shedder design was specified. During an FSA for the SIS, the selection of this flow meter was questioned. After some investigation it was determined that the two-headed design was a prototype for the manufacturer, and that there was no data at all on its performance. The design had not even been flow tested in the lab. The FSA report recommended that this device not be used in SIF applications.
- A Process Licensor specified a feed gas specific gravity analyzer be used in correcting a feed flow measurement, and that the corrected value be used in the unit master shutdown. The system was installed as specified by the licensor, and within the first week of operation a spurious trip occurred due to a brief power interruption to the analyzer. It was suspected that a technician had mistakenly shut off power and then turned it back on after realizing their mistake. The shutdown system saw the dip and tripped the unit on low flow. As a result, the analyzer was taken out of the flow correction calculation.

Some general thoughts on specification of input instrumentation
- The SRS for SIF’s should specify functional requirements for input instrumentation such as the basic instrument type, required accuracy of the instrument and the trip point, and the measured range. The SRS should also identify the service severity of the process measurement (high temperature, high pressure, corrosive, high vibration, etc.).
- Input instrumentation should be selected from types for which the User has significant experience and be as basic as possible. Process Safety related instrumentation is not a place to try out new stuff. Complex instrumentation, especially analyzers should be kept out of any shutdown applications. Where possible, the User should have a list of qualified instrumentation, either due to prior use experience or vetting though manufacturers service data or third party certification.
- Input instrument ranges should be selected to provide a live measurement at normal operating conditions and have sufficient signal margin around the trip point to provide a reliable indication of a trip condition. This can be a problem in some applications such as low flow trip that uses an orifice plate and DP transmitter. There is a square relation between signal and flow, so a trip set point of 10% of the instrument’s flow range is actually only 1% of the DP transmitter signal. This is generally too low of a signal to reliably indicate a trip condition so either the trip point needs to be raised or a flow measurement method that doesn’t have this behavior should be considered.
It should be noted that many times a trip point is specified based upon maintaining a comfortable margin between normal operation and trip conditions, and that sometimes a too wide of a margin is specified. There is a balance between maximizing this margin and specifying a trip point that is too low to reliably measure.
Final Element Design

Final elements need to be carefully considered for their availability and reliability in being able to bring a process to a safe state. Shutdown valves need to be selected based upon high reliability so they should be of a design where critical parts are not overly subjected to severe process conditions.
For SIF’s the allowable leakage across closed shutdown valves needs to be specified and needs to recognize the realities of how valves behave in real services. Those with operational experience know that no leakage specification survives the first day in process service.
Dedicated shutdown valves with open flow paths and whose critical seating surfaces are protected during the 99.99% of the time the valve is open should be considered. Standard control valve designs typically should not be used where plugs and seats may be subjected to process wear and high pressure drop. Sharing of control valves in shutdown designs is often considered in order to save the cost of a trip valve but in my view doing so to avoid an extra trip valve is usually false economy
Stroking speed needs to be carefully considered and oversized actuators that can break any sticking forces that develop over time are not a bad idea. Actuator designs should be fail-safe and use of double acting actuators or motor actuators should be avoided. Where non fail-safe actuator designs are used, the loss of motive power such as air supply or motor power must be included in PFD calculations and the motive power sources fall under the testing and MOC requirements for SIF’s.
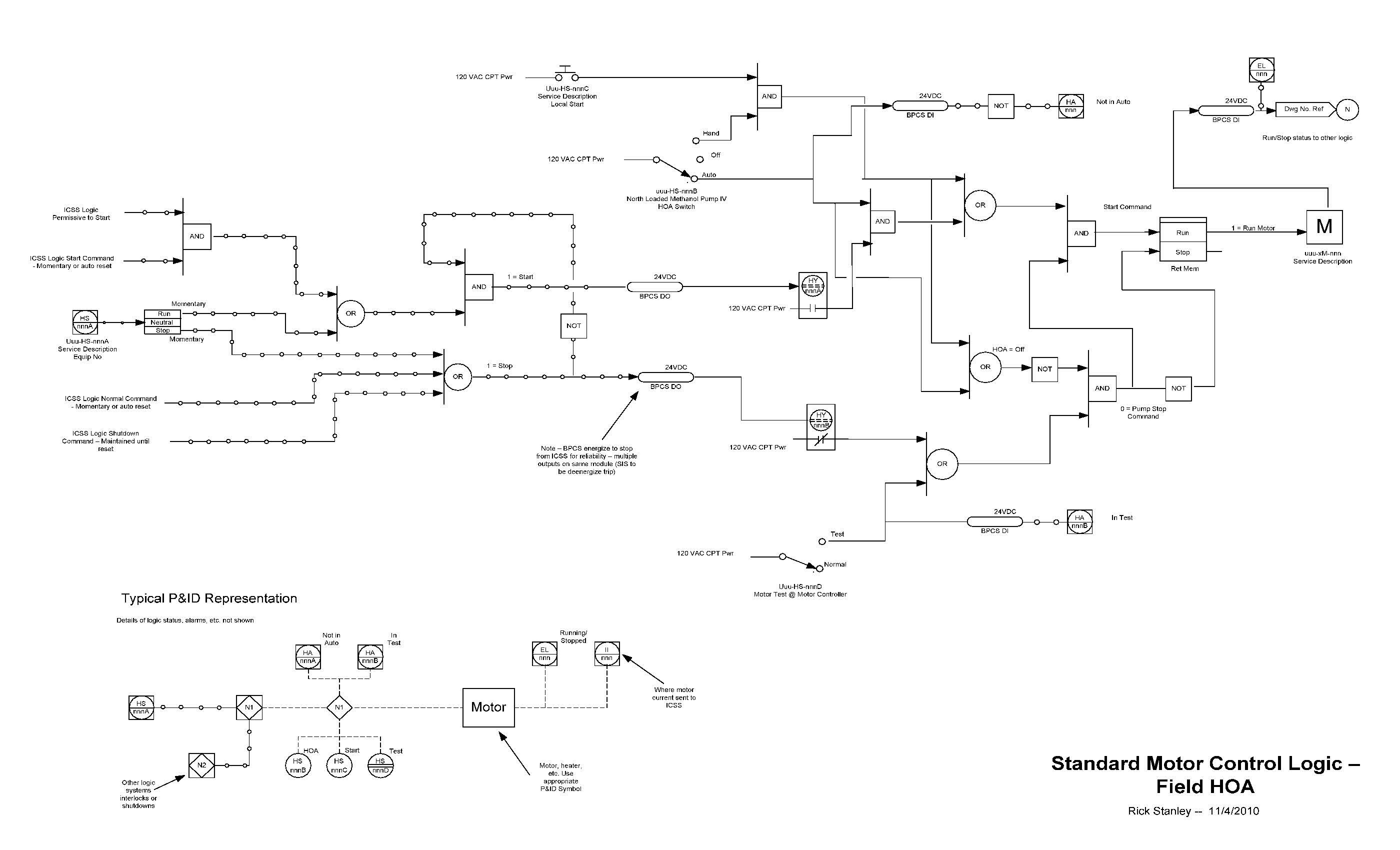
Most shutdown valves use a solenoid valve to vent air off the actuator. Single solenoid valves are subject to spurious trips should a coil burn out or a circuit problem occur. A common application is to use 2oo2 solenoid valves for shutdown valve services. This provides high reliability and allows for frequent online testing. Some of the original home-grown designs with which I was involved were fairly expensive to implement but justified considering the costs of spurious trips. Since then commercial packages with full diagnostic and testing functionalities are now readily available on the market.
Shutdown services may include shutting down of motor driven equipment. Usually a SIF or Interlock that shuts down a motor uses 1 or 2oo2 interposing relays, but often the designer doesn’t consider the reliability of the motor starter itself. This is a particular issue with high voltage, high power motors that use full blown switchgear to operate the motor. These applications usually have an energize to trip motor trip coil, so the performance of this SIF is often dominated by the availability of switchgear power. When a energize to trip motor controller is used, the power systems for that system now fall under the testing and MOC requirements that apply to any SIF.
Independence
The design needs to be independent from other IPL’s or from the IPL’s Initiating Causes. For example, a high-pressure alarm that warns of failure of a pressure control loop requires its own pressure transmitter and process connection.
Instruments associated with a SIF should not share services with BPCS functions, although some organizations allow for minimal sharing, such as allowing one of three transmitters in a 2oo3 voting scheme to share inputs with a BPCS loop. This requires some special attention as now there are two functions involved when maintaining or testing the field instrumentation. In these designs, the transmitter should directly drive SIS inputs using SIS power. The input to the BPCS should be taken from an isolator that will not affect the SIS loop performance if the BPCS circuit is broken
Reliability
While HAZOP’s and LOPA’s concentrate on the required availability of protective functions, in most real plants, reliability is every bit as important. IEC 61511 says almost nothing about reliability and leaves it to the User to figure it out. A key part of specification of any protective function is determining the effect of spurious trips upon a process unit. A spurious trip introduces both process safety risks and commercial risks. It is an adage in the process industries that the highest risk periods are during a unit startup or shutdown. When a unit experiences a spurious trip, the lost production while the unit is secured and restarted, even if no damage has occurred, can be significant. Some processes can take days to restart, and loss of production is measured in the hundreds of thousands to millions of dollars. When an SRS is prepared for SIF’s, the costs and safety risks associated with spurious trips should be identified and specific reliability requirements included.
Process Safety risks are even more of an issue when the shutdown is a crash induced by a protective system’s spurious trip. When a unit is crashed, all sorts of bad things can happen. Hot joints that cool down too quickly can leak or even cause significant loss of containment. Equipment can also be damaged. Some process types are especially intolerant of unit crashes, such of Fluid Catalytic Crackers. A sudden shutdown can result in damage to refractory damage or plugging systems with catalyst or heavy oil. It’s bad enough that an FCC may take days to restart, but if refractory damage occurs, that interruption can spread to weeks and the repair costs can be significant.
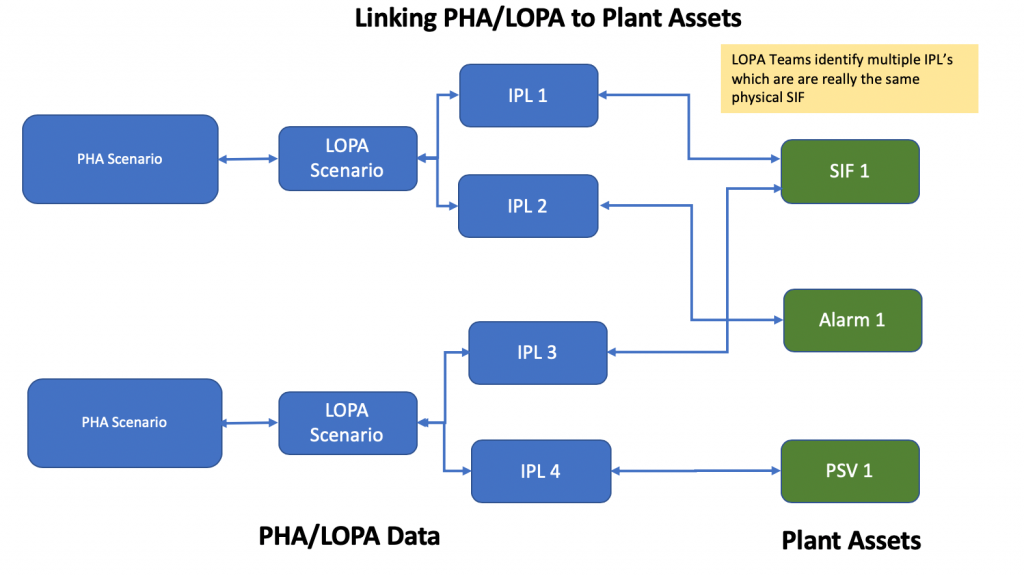
The net result is that the costs associated with spurious trips can justify a lot of reliability features in field instrument design. The most common method is the use of voting logic that tolerates a level of faults in the field instrument. Schemes such as 2oo3 or 2oo2d can provide high availability and are tolerant of failures in field instrumentation. I’ve seen places where it was decided to not provide robustness in order to save a transmitter or reduce SIS programming. Those kinds of decisions are usually false economies. Usually the cost of adding robustness to a trip function is covered in the first few minutes after a false trip occurs.
Another aspect of selection of instrumentation for Process Safety Services is to avoid the use of switches. At one time process switches such as float levels, pressure and DP switches, etc. were very common. Their long service history has demonstrated their unreliability. A process switch sits dormant for extended periods and there is no way other than frequent testing to verify whether a process switch is operable or not. As a result of the many improvements made in continuous process measurements and of programmable logic solvers, the justification to use what were perceived as cheaper instruments has become moot. Almost every current standard or recommended practice discourages, or even forbids the use of process switches in Process Safety Services.
Spurious trips can also be significantly reduced by selecting the proper field instrumentation. As discussed above, the field instruments should be a simple and robust as possible. Where an orifice plate and DP transmitter will do, it’s far preferable to use these relatively simple and tried design vs. a complex flow transmitter that may experience signal drop-outs or failure modes that are not well understood.
Accuracy is another area where instrumentation in shutdown services gets over specified. The basis for the specification of a trip point in a SIF or Interlock needs to be clearly understood when field instrumentation is being specified. If the trip point is specified to protect against a specific equipment limit, high accuracy may be required. But if the trip point is needed only to detect when a process has had a failure that can result in hazards, such as a low flow caused by the failure of a pump or compressor, the trip point may be specified only to provide a comfortable operating margin. In these cases, accuracy may not be such a big deal. Attempting to provide highly accurate field instrumentation in a situation where that accuracy isn’t needed can result in designs that are not as reliable as they should be.
Maintain and Test
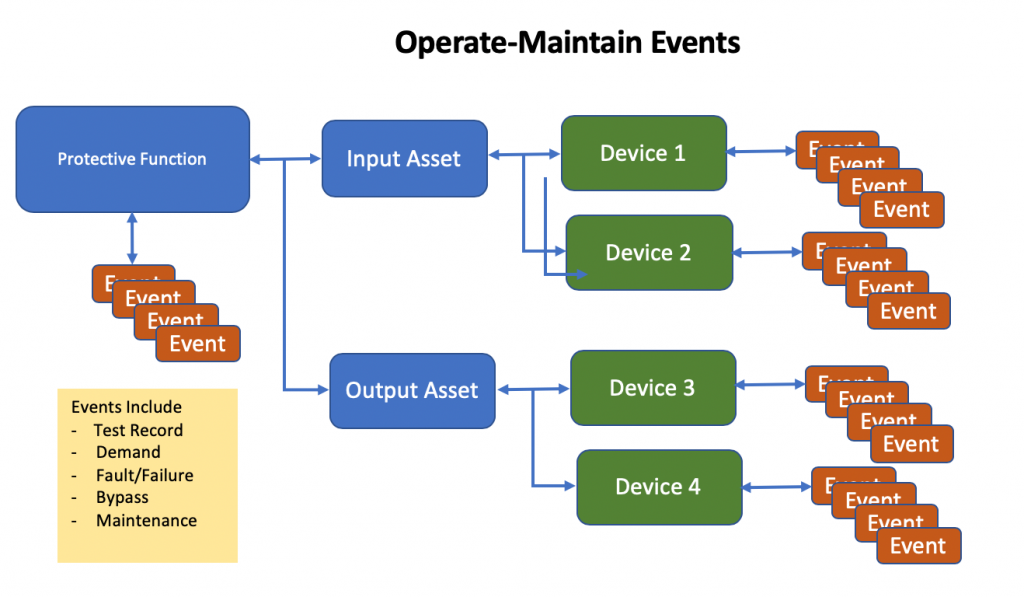
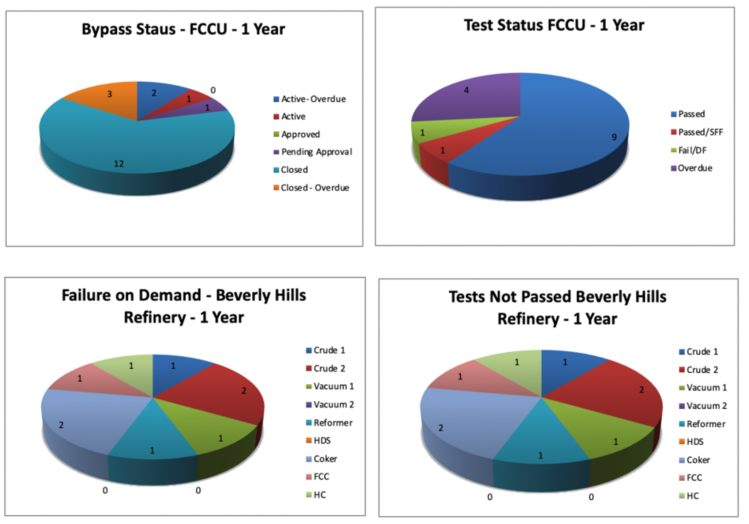
All field instrumentation in Process Safety Services needs to be periodically tested. The frequency of testing is based upon the failure rates of the types of devices being used and the performance requirements of the service. Intervals can vary from quarterly to several years apart. In many instances, the test interval is more frequent than the Unit turnaround or outage frequency and provisions must be made for testing while the Unit is in operation.

Testing provisions can take a number of forms, including
- Provisions for bypassing of Input signals within the Safety Function logic
- Provisions for bypassing of commands to final devices
- Provisions for bypassing of final devices themselves
- Other on-stream testing provisions such as partial stroke testing
My preference has always been to design testing systems so that the final elements such as valves or motor starters can be bypassed for testing, and that the SIS logic includes detection of when a system is properly isolated and safe for testing. This isolates the trip functions from the inputs and allows for full testing from end to end without running the risk of false trips. Motor starters are difficult to test as generally they can’t be tested without shutting down the motor. Fortunately, the failure rates of motor controllers are low relative to other devices and seldom does the motor controller (other than power for energize to trip switch gear) factor into test interval calculations. However, testing of motor starters at every unit shutdown should be part of any testing program.
Voting systems are usually used in SIF services to provide both availability and reliability. Voting systems can also simplify maintenance of field instrumentation while the SIF and its process are in service. My preference has always been to use 2oo3 voting on inputs, with degradation to 2oo2 during the periods when one of the input instruments has failed. The 2oo3 scheme allows for one instrument to fail and allows one instrument to be removed from service for maintenance with minimum risk of a spurious trip occurring. The fall back to 2oo2d tends to protect against maintenance errors that might take out a second transmitter. In any event, detailed procedures for working on Safety Related instrumentation should be developed during their design.
I also prefer that physical bypass piping and a bypass valve be used with trip valves. In most installations the cost is nominal compared to the costs of a false trip caused during testing. The bypass valve should be equipped with position indication that allows the logic solver to verify that the valves are in bypass before allowing testing to proceed, and which provides an alarm whenever the bypass valve is not fully closed.
Many valve manufacturers offer functionality to support partial stroke testing during ongoing operations. This function results in the valve being commanded to move to some partially closed position, typically 10 to 20% of stroke (90 to 80% open) and then return to a full open position. This hasn’t been a real attractive alternative for me. It complicates the installation, often requiring an expensive smart valve positioner to facilitate the testing in addition to trip solenoid valves. Partial stroke testing also makes life harder for instrument technicians who require special training to partial stroke tests. Newer designs do allow for partial stroke tests to be automatically scheduled and executed, which reduces the probabilities of human error.
There are installations where partial stroke testing is justified, such as a requirement for very frequent testing or for large or very high-pressure valves where installation of a bypass for testing is impractical or just too expensive (that high-pressure piping takes up a lot of space). Some organizations have embraced partial stroke testing, but his requires commitment to fully understanding how these functions work and owning and using the additional software required to set up stroke testing and analyze the results.
Conclusions
The performance and reliability of field instrumentation is critical to the safe performance Process Safety Protective Functions. Proper and complete performance requirements need to be clearly defined in documents such as Safety Requirements Specifications. This includes specification of all set points and the basis for the selection of those set points.
The selection of field instrumentation should be based upon proven performance and well-known characteristics and failure mechanisms. The designs must include provisions for maintenance and testing over the life cycle of the instrumentation. Overall designs should be simple as possible but include provisions for high reliability and simple and safe maintenance and testing. Overly complex selections, or systems not designed for high reliability typically result in poor performance, excessive spurious trips and the accompanying high costs of operation and overall reduced safety of operation.
Rick Stanley has over 40 years’ experience in Process Control Systems and Process Safety Systems with 32 years spent at ARCO and BP in execution of major projects, corporate standards and plant operation and maintenance. Since retiring from BP in 2011, Rick formed his company, Tehama Control Systems Consulting Services, and has consulted with Mangan Software Solutions (MSS) on the development and use of MSS’s Safety Lifecycle Management software.
Rick has a BS in Chemical Engineering from the University of California, Santa Barbara and is a registered Professional Control Systems Engineer in California and Colorado. Rick has served as a member and chairman of both the API Subcommittee for Pressure Relieving Systems and the API Subcommittee on Instrumentation and Control Systems.