How to Manage Bypasses Using SLM
How to Manage Bypasses Using SLM
IEC 61511 Part 1, contains extensive discussions of the design and operating procedures for SIF bypasses. Clause 16.2 describes operational requirements such as:
- Performing a hazard analysis prior to initiating a bypass
- Having operational procedures in place for when a protective function has been bypassed
- Logging of all bypasses.
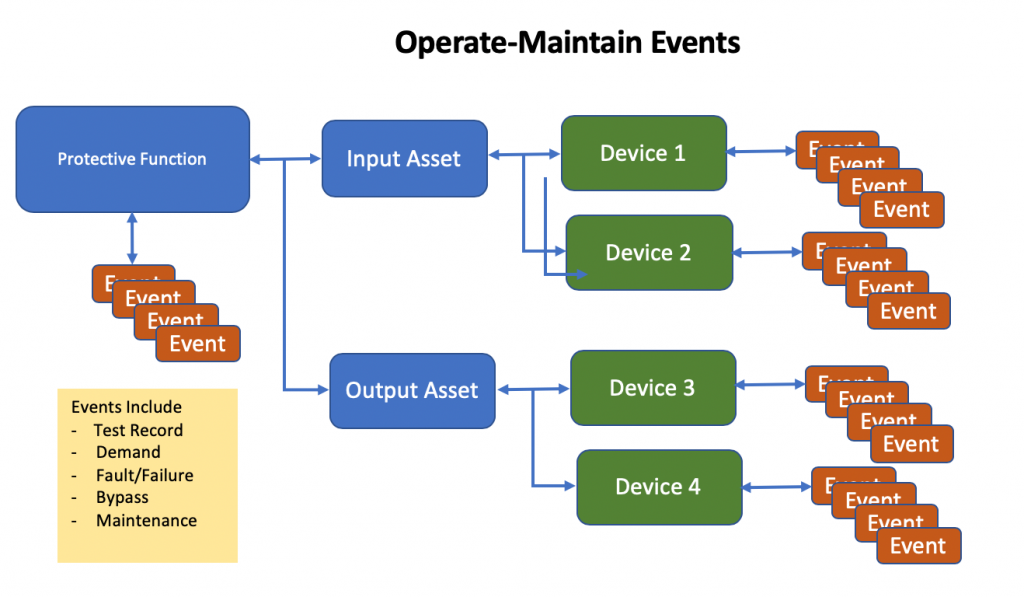
How to Manage Bypasses Using SLM – through a robust Bypass management and logging function that meets all of the requirements of IEC-61511 and integrates with the performance analysis and reporting functions of the SLM Operate-Maintain (OM) Module. SLM OM Module uses the Bypass Authorization object and Work Flow to initiate, approve and record the execution of Protective Function Bypasses. SLM does not limit the use of Bypasses to just SIFs. In SLM, any protective function may have a Bypass Authorization associated with it.
Read more about the Benefits of Effective Bypass Management
The figure below illustrates how the Work Flow supports the tasks required on how to manage bypasess using SLM:
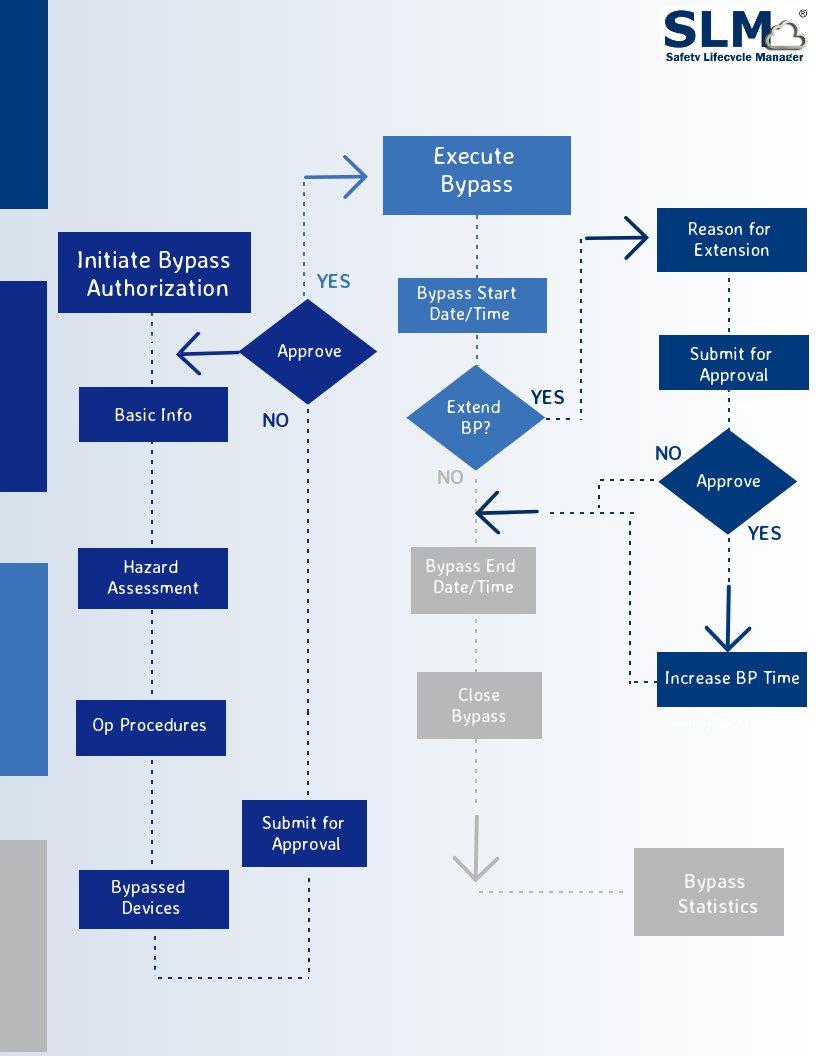
A Bypass Authorization is initiated by any authorized SLM user. In practice this will usually be a member of the Operations Staff for a Unit, often a shift foreman or Operations Engineer. The originator is guided to enter the information required to support the Bypass Authorization. This includes:
- Basic Bypass information such as the reason for the Bypass, the anticipated start date and time and the maximum time which the Protective Function is to be Bypassed
- Hazard Assessment information – this includes an identification and assessment of the potential severity of hazards that may occur while the Protective Function is Bypassed and the corrective measures that should be taken if the hazard occurs
- Operation Procedures that are required to be used to mitigate potential hazards that may occur while the Protective Function is Bypassed
- Identification of the Devices associated with the Protective Function that will be Bypassed
Once this information is provided, the user then may submit the Bypass Authorization for Approval. The Bypass Authorization is submitted to the designated Approver, typically an Operations Supervisor of Manager. The Approver reviews the Bypass Authorization and either Approves or Disapproves the request.
Once the Bypass Authorization is Approved, the Operations team may execute the Bypass as planned. The originator or other authorized user may then record the start date and time of the Bypass in the Bypass Authorization. If a Bypass is expected to exceed the time requested in the original Bypass Authorization submittal, the user may request approval for a Bypass Extension by filling in the data in the Bypass extension section of the Bypass Authorization object. When approved, this will update the authorized Bypass time and prevent the Bypass from being reported as exceeding its authorized time.
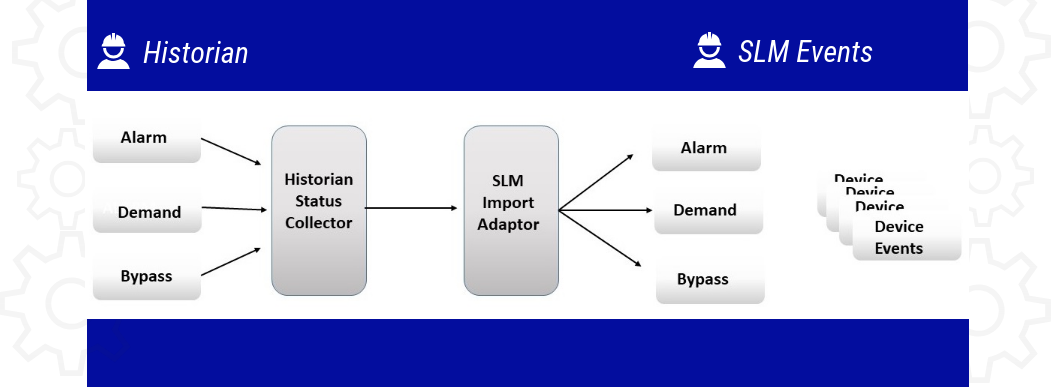
When the Bypass is completed, the originator or other authorized user then enters the date and time when the Protective Function is returned to service and then close the Bypass Authorization. Closing of the Bypass Authorization results in the Bypass data being added to the SLM Events that are used to analyze Protective Function and Device performance.
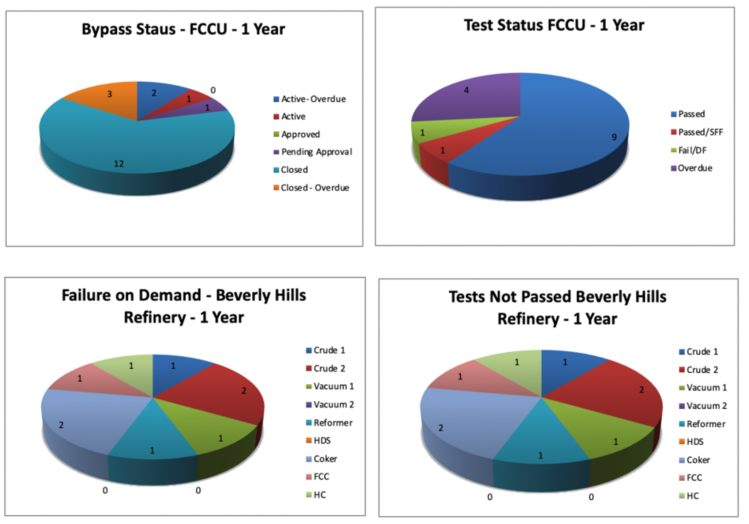
SLM contains performance views that capture all Bypasses for a Function, Unit and Site. The analysis functions include reporting on the number of bypasses, time in bypass and identification of Bypass Events that exceeded the authorized bypass time. SLM will also compute the effect of Bypasses on a Protective Function’s in-service performance, such as computing the in-service reduction in the Functions’ RRF or PFD. Functions that have excessive Bypasses will also show up on the Unit and Site bad actors lists.
Rick Stanley has over 40 years’ experience in Process Control Systems and Process Safety Systems with 32 years spent at ARCO and BP in execution of major projects, corporate standards and plant operation and maintenance. Since retiring from BP in 2011, Rick formed his company, Tehama Control Systems Consulting Services, and has consulted with Mangan Software Solutions (MSS) on the development and use of MSS’s Safety Lifecycle Management software.
Rick has a BS in Chemical Engineering from the University of California, Santa Barbara and is a registered Professional Control Systems Engineer in California and Colorado. Rick has served as a member and chairman of both the API Subcommittee for Pressure Relieving Systems and the API Subcommittee on Instrumentation and Control Systems.