What really should be in a Safety Requirements Specification (SRS)?
What really should be in a Safety Requirements Specification (SRS)?
IEC 61511 ed.2 and ISA 84.00.01 require that a Safety Requirements Specification (SRS) be prepared for each Safety Instrumented System (SIS). Clause 10 describes the requirements for the SRS. Clause 10.3.2 lists the minimum items that shall be addressed in the SRS. A total of 29 items are listed.
In my experience (over 40 years) reviewing SRS’s produced by multiple organizations, the authors typically don’t read or understand the requirements, nor do they understand the overall intent of the SRS. Many I have reviewed have missed the mark badly. In many cases, the SRS has been treated as an “after the fact” document and as such has been bloated with tons of detailed design information while missing a majority of the standard requirements. When you actually dig into an SRS you typically find all sorts of things have been left out while the main focus tends to be on documenting what the engineers did. The sad thing is that some of these SRS’s have been produced by reputable companies that market themselves as SIS experts.
The first thing to know is that the SRS is required to be a “before design starts” document. The intent of the committees that wrote IEC 61511 ed. 2 and ISA 84 was to ensure that the SIS requirements be laid out before design starts, and to define the things required to be addressed during detailed design. The SRS is NOT a detailed design document. The SRS is used to guide detailed design of the SIS and should then be used to verify that the design actually meets the requirements. Any Organization that does not require that a complete SRS be prepared and approved prior to the start of detailed design isn’t in compliance with the RAGAGEP and thus is likely to be spending way too much money during the detailed design phase. If you have an SRS that conforms to the standards, the subsequent detailed design becomes a lot less expensive and is more effective.
That said, an SRS isn’t necessarily a short document, but it also doesn’t need to be a huge pile of papers that most become. AN SRS is not easy to write the first time around-I look back at some of my first efforts and cringe a bit. In order to be effective, there is a lot of learning that needs to happen. It’s really a good idea to be able to have a quality SRS example to work from if you are developing your first one.
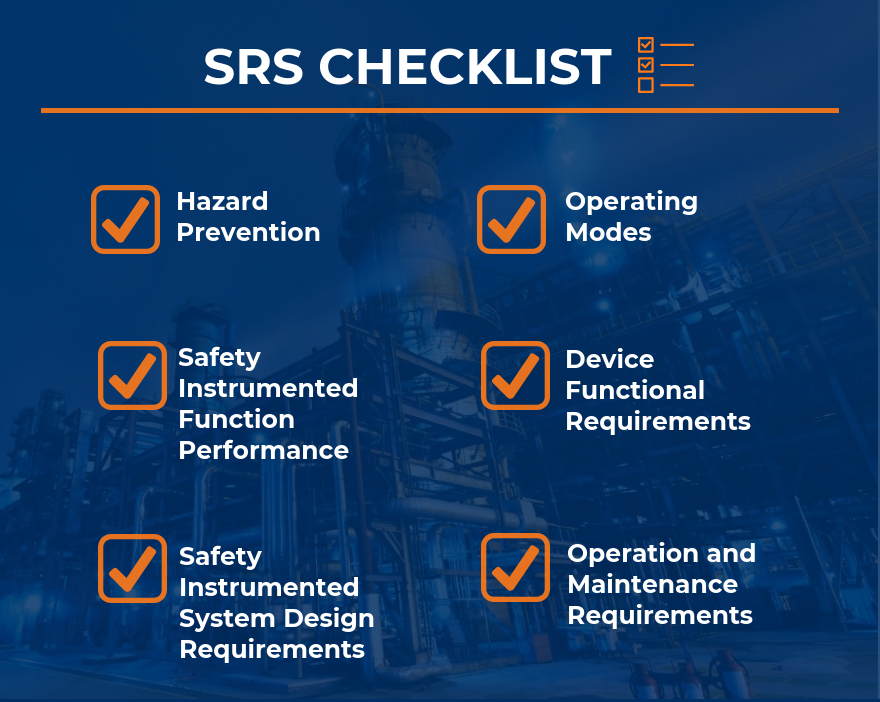
An SRS should be focused on the following broad areas. Coincidentally, many of these areas are what are missing from the SRS’s I’ve seen. Within each of these, the items defined in IEC 16511/ISA 84 Clause 10.3 need to be included.
- Hazard Prevention – The SRS needs to clearly identify the Hazard for which each of its Safety Instrumented Functions (SIF) is intended to prevent and the functions that the SIF’s must perform.
- Operating Modes – The SRS needs to define when the SIF’s are required to be available and when they are not. The SRS needs to describe how and when a SIF is put into service and also how and when it is bypassed or removed from service. These descriptions need to be explicit and define what the detailed design needs to enable.
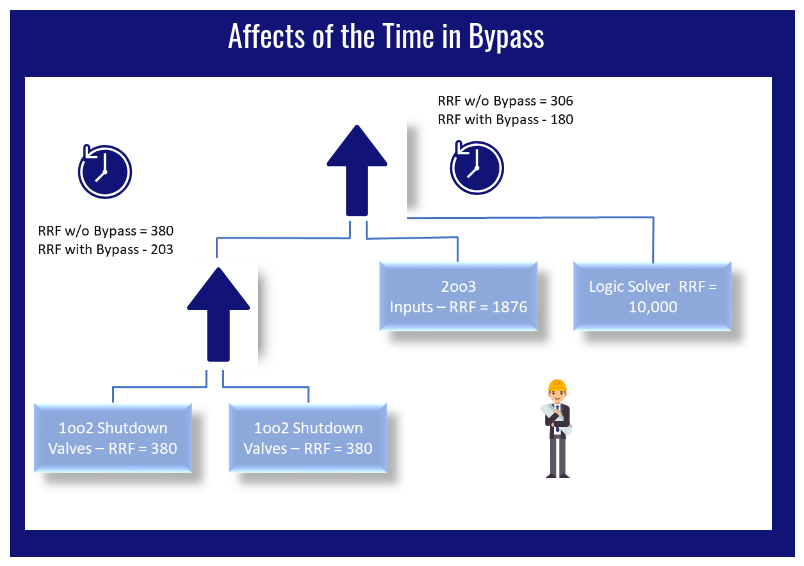
- SIF Performance – The SRS must define the performance requirements for each SIF. IEC 161511 ed. 2 and ISA 84 are big on making sure that the SIF activates upon demand (this is usually categorized as a Probability of Failure upon demand (PFD). They aren’t as focused on the reverse, which is making sure that false trips don’t occur. The owner of the SIS needs to make sure the SRS addresses design requirements for both Availability (PDF) and Reliability (prevention of false trips). This means defining requirements for redundancy, voting groups, and similar design features that promote reliability without compromising availability.
- Device Functional Requirements – The SRS needs to define the performance expectation for field devices such as:
- Range
- Accuracy
- Response time
- Shutdown valve stroke time
- Leakage
- Certifications for use
These are performance requirements and are not procurement specifications.
- SIS Design Requirements – The SRS needs to identify the specific SIS and SIF design requirements and they need to address organization and site practices such as:
- Acceptable component selection
- Installation requirements
- Wiring requirements
Note: It’s best that an organization produces a SIS Design Standard as a reference and not try to cram this data into the SRS. Some organizations have two Standards. Once for SIS physical design and installation and a second for SIS application software and programming.
- Operation and Maintenance Requirements – The SRS needs to define testing and verification requirements for the SIS and its SIF’s over the SIS life. The SRS should define what procedures must exist such as:
- Operating Procedures
- Initial Validation
- Periodic Test Procedures
- Bypass Procedures
- Performance Data Records
- Periodic evaluations
The SRS doesn’t need to include these procedures but needs to identify the requirement that the procedures be developed and used.
What you don’t see in the items listed above is anything about doing data sheets or design drawings, etc. Those all come later and should never show up in an SRS. If an organization wants to produce a design book, that’s fine, but its separate from the SRS.
Rick has a BS in Chemical Engineering from the University of California, Santa Barbara and is a registered Professional Control Systems Engineer in California and Colorado. Rick has served as a member and chairman of both the API Subcommittee for Pressure Relieving Systems and the API Subcommittee on Instrumentation and Control Systems.