How to Use Your Process Historian to Generate Automated Safety Lifecycle Manager (SLM) Events
How to Use Your Process Historian to Generate Automated Safety Lifecycle Manager (SLM) Events
Capturing Events in SLM generally requires manual entry of data by a user. However, this doesn’t need to be the case. It is possible to automatically extract Event data from a Process Historian. Setting it up takes some initial work, but once the setup has been done, the process of Event generation can be automated.
First, the user must have tags that exist in the basic process control system (BPCS) and Historian from which the Historian can capture changes in status. These are status tags that signify that an Event has occurred. A few examples of this are:
- Alarm Activation
- Safety Instrumented Function (SIF) Demands
- Manual Trip Commands
- SIF Bypasses
- Fault/Failure Diagnostics
- BPCS demands
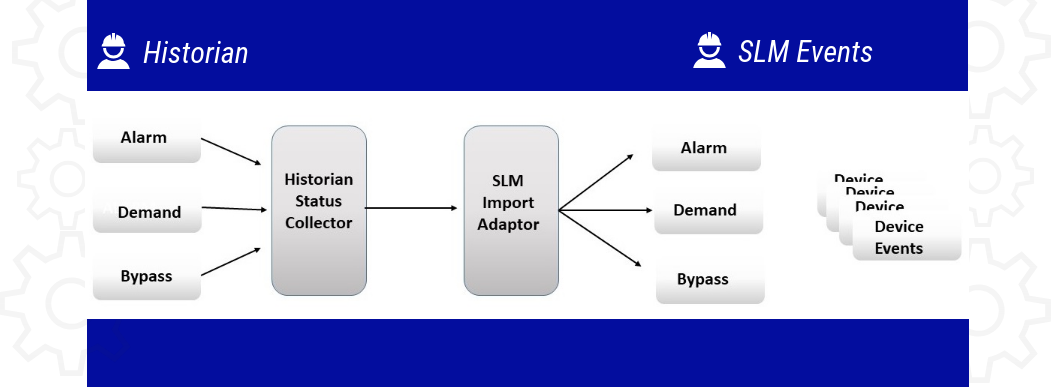
In order to leverage this functionality, the underlying BPCS, Safety Instrumented System (SIS) alarm, and status tags need to be developed. See example in the figure below:

Then, once the necessary status data is available in the Historian, an external scanning program needs to be developed that will scan the Historian data for a set of tags on some routine basis, typically daily, but other intervals may be chosen.
The scanning program exports a file with a list of all status changes that occurred over the scan interval. Typically, this file contains the tag number of the tags associated with the status change, the status change (e.g. from Normal to Tripped, Normal to Bypass, Bypass to Normal, etc.) and the time stamp of the status change. On the SLM side, another program, the SLM Import Adapter, examines the Historian export file and generates the associated Event in SLM. In order to do this, SLM needs to have a table of the tags which may have a status change and enough information to allow SLM to generate the Event. Some of the information required is:
- The Historian tag name and the SLM object name – These should be the same, but there is no guarantee they will be.
- The type of Event with which the Historian tag is to be associated (e.g. Demand, Bypass, etc.)
- A list of Devices associated with the SLM object name for which SLM should create Device Events
- Whether the Event is to be directly logged in SLM or submitted for Approval.
The SLM Import Adaptor is then used to generate the SLM Events. The Adaptor handles the messy behind the scenes details of creating the Events and any linkages to SLM Parents or Children.
However, it should be noted that Historian tag status data cannot always provide all the data that a user may want to support SLM’s performance analysis and reporting functions.
For example, a SIF Demand Event generated from Historian data will record a SIF Demand in SLM, but probably won’t have enough data available to verify whether the Demand was executed successfully or identify what Devices were involved in the Demand.
It will usually be necessary for a user to review the automatically generated Event data and supplement it with additional information such as Pass/Fail status or creating or editing Device Events that should be associated with a Demand. This can be addressed by requiring that all automatically generated Events be entered into the SLM database as requiring Approval. This clearly identifies that new Events have been created and allow for review and completion prior to finalizing the Event.
While we have been discussing how SLM Events can be generated from Historian data, the same concepts can be applied to other Events such as Testing and Maintenance Events where data can be extracted from a Site’s Maintenance Management System and imported to SLM Events.
Rick Stanley has over 40 years’ experience in Process Control Systems and Process Safety Systems with 32 years spent at ARCO and BP in execution of major projects, corporate standards and plant operation and maintenance. Since retiring from BP in 2011, Rick formed his company, Tehama Control Systems Consulting Services, and has consulted with Mangan Software Solutions (MSS) on the development and use of MSS’s Safety Lifecycle Management software.
Rick has a BS in Chemical Engineering from the University of California, Santa Barbara and is a registered Professional Control Systems Engineer in California and Colorado. Rick has served as a member and chairman of both the API Subcommittee for Pressure Relieving Systems and the API Subcommittee on Instrumentation and Control Systems.