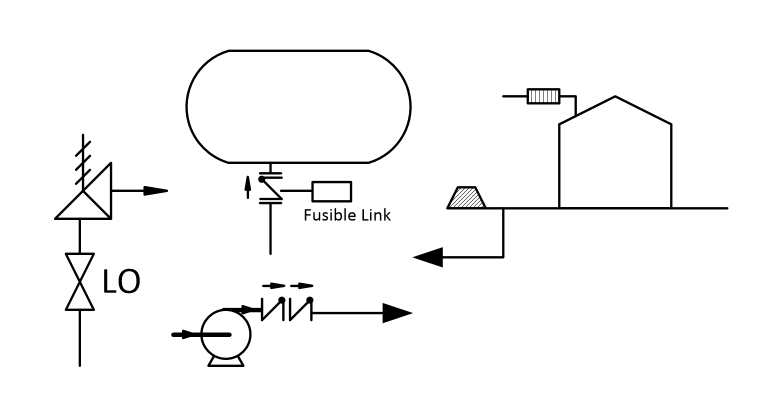
Tank Berms and Dikes
One of the most common non-Instrumented IPLs is installation of Berms and Dikes (Bunds if you are outside of the US) that contain the contents of a storage tank or vessel should there be a loss of containment event. Berms and Dikes get a fair amount of attention during their initial design, but soon become just a background feature in the tank farm. Over time, they can degrade or be compromised by ongoing operations.
One of the more recent and spectacular failures of containment IPLs is the Buncefield storage facility fire that occurred in the UK in 2005. As with most major incidents, there were a number of contributing causes, but one of them was the failure of the tank containing walls to contain the liquid released by a tank failure. This allowed inventory to escape the secondary containment. The investigation of the incident found that seals in the concrete wall containment system had not been maintained and significant material flowed beyond containment.
Drainage Systems
When sizing pressure relief systems, credit is often taken for the presence of drainage systems that will prevent the accumulation of flammable liquids around process vessels. This allows the designers to eliminate or reduce the size of the pressure relief systems for fire cases. A drainage system consists of physical grading or installation of drainage trenches or lines that carry away flammable material to a “safe location”. These systems are usually dry for years and decades and aren’t that hard to compromise. Drains and trenches can become plugged with debris or the “safe containment” area gets compromised or even built over. The Buncefield fire and explosion mentioned above was aggravated by the fact that the drainage systems failed to function as they were designed, and material that leaked from the tank containment did not flow away from the area as intended.
Frangible Tank Roofs
Storage tanks are subject to overpressure from a variety of sources as described in API RP-2000. For the more extreme cases, such as external fire, designers may choose to specify that the that tank be constructed with a weak roof to wall connection, or a frangible roof. The design is intended to provide a failure point which would allow a path to relieve vapors generated prior to failure of the tank at more catastrophic locations such as at the floor to wall seam.
The difficulty with constructing tanks with a frangible roof specification is that externally it is extremely difficult to verify that the welds at the roof seam meet the requirements for a weak seam. In tank over pressure audits conducted many years after tank construction, it was found that it was basically impossible to verify that the existing tank roof to wall welds qualified as a frangible roof. During the study, a few reports of welds not meeting frangible roof specifications were found. There is no practical means of testing the seam, so there was little alternative other than to not take credit for a frangible roof, which resulted in retrofit installation of some very large emergency roof vents.
Excess Flow Valves
Excess flow valves are typically installed to prevent the uncontrolled flow of hazardous material from a vessel to the environment should an external failure occur, such as failure of light ends pump seals or other loss of containment events involving equipment downstream of the process vessel. They are also found in transportation applications such as truck loading racks or in pipelines.
In regulated industries such as transportation and pipelines, excess flow valves typically have high visibility and usually get tested and maintained. However, in process applications, this isn’t necessarily the case. Process excess flow valves are often installed at the outlet of a process vessel and are of a design that uses a check valve installed in a reversed position. The check valve is held open by a mechanical linkage that is released by either a fusible link that melts when exposed to a fire or a solenoid valve that releases the linkage, and sometime both.
Once installed, these valves appear remarkably common. They look like most any other check valve and often get ignored and sometimes forgotten about. I recall being in an older process unit on other business when I just happened to notice a couple of wires hanging from an open conduit. In itself this was a big issue as if those wires were energized an ignition event could occur. So, I started to look around and found an old, solenoid operated excess flow valve nearby that was missing its wires. Worse yet, the excess flow valve hadn’t operated. A bit of inspection showed that the solenoid was indeed deenergized, but the mechanical latch mechanism was severely corroded and had not allowed the valve to operate. Even more interesting was when I reported this to the Operations group, they had no idea that the excess flow valve was there. No wonder it never got looked at. The wiring disconnection appeared to be some casual modification that no one had any idea of when or who did it, or why. This incident started a hunt for other excess flow valves in the plant, which turned up another handful of issues. After decades of neglect, the excess flow valves got added to an inspection and maintenance list.
Check Valves
In high pressure applications, such as feed pumps for hydrocrackers, other services where liquid is being pumped from a very low pressure to a very high pressure, or when a high pressure process can back flow into a low pressure process, check valves are often depended on to provide some level of overpressure protection for the low pressure system. API RP-521 recognizes this practice and recommends that credit only be taken for installations consisting of two check valves of differing designs installed in series and describes considerations that should be used in assessing potential leakage through the check valves.
The difficulty in operating these systems is that almost every pump in a process plant has at least one check valve installed in its discharge lines, so keeping track of which check valves are being credited for over pressure protection can be a challenge. It’s quite easy to lose track of these valves and not give them the routine inspection and leak testing required for those services which are being used at IPLs or to reduce the low-pressure relief system requirements. The check valves that are used for these purposes are usually high-pressure designs (2500 or 1500 pound class) and are difficult to maintain due to weight and sometimes being installed with welded ends. At the same time, the hazards of a failed check valve service are quite high, as high-pressure backflow will generally result in the rapid unscheduled disassembly of the low-pressure equipment.
Flame Arrestors
Flame arrestors are static device, usually consisting of some form of metal mesh or similar convoluted flow passages at the location where a tank or other vessel is vented to atmosphere. Flame arrestors are designed to prevent flame propagation from the vent outlet back into the tank or vessel, usually by cooling an external flame and reducing the flame propagation velocity.
Flame arrestors are passive devices and may remain in place for many years without any attention. This often results in the functionality being compromised due to build up of dirt, insect nests, corrosion or other degradation. Flame arrestor design is also based upon a very specific set of conditions such as the flammable material contained in the tank and environmental conditions. It is not that difficult to compromise or plug up a flame arrestor, and there are reports of them failing to function when needed or being found in an inoperable condition when inspections were eventually performed.
Block Valve Lock Systems
In some process designs, safe operation of the process is depended upon block valves installed for maintenance, startup or shutdown operations being kept in specific positions, either opened or closed. For example, pressure relief system designs are often dependent upon block valve installed under pressure relief devices being kept open at all times, or other block valves required to isolate parallel equipment being kept open whenever process fluids are in the system.
Often block valve lock systems are manually managed with only manual monitoring. The physical “lock” varies with the operations, ranging from simple aluminum car seals such as those used on rail cars or truck doors, to new plastic designs, to designs that used metal cables or chains with physical locks. In some cases, an organization will attempt to not use physical barriers and rely only upon hanging warning tags on valves.
Use of block valve lock systems requires that there be a robust administration system whereby the status of all locked open or closed valves are continuously kept and logged, and that procedures to follow when removing or installing a block valve lock/seal and changing of the valve positions are clearly specified and followed. If locking systems are used, an additional layer of tracking of keys is also required.
For a process plant of any size, there may be a large number of block valves that are designated as CSO, CSC, LO, LC etc. (Car Seal Open, Car Seal Closed, Locked Open, Locked Closed). Administration of these valve seals or locks is no small task and more than a few units have failed surveys of their valve lock systems.
Captive Key Systems
Captive key systems are a step above the use of simple valve seals and locks. In most cases, captive key systems are used in applications where a number of valves or other equipment must have their status changed in a specific order. In these systems, the valves or other operating equipment are provided with a mechanism that requires that a key be used to unlock the valve or system for operation. The mechanism captures the initiating key when the operation is performed and releases another key that is used to operate the next valve or system in the sequence. The system has multiple keys, all of which are different. When using a captive key system, the operator starts with an initiating key that is used to operate the first device in the chain. Keys are trapped and released in sequence, with the final device releasing a key that then is stored in a safe location. When the sequence is to be reversed, the operator starts with the final key and the sequence is reversed.
Captive key systems are often used to assure that equipment is safely isolated for entry or maintenance, such as in high voltage electrical systems, or in systems that require a large number of sequential valve movements to isolate equipment such as a spare reactor. The challenges of ownership are administration of the starting and ending keys, so they do not get lost and keeping the various locking mechanisms clean and operable. The use of these systems is often very infrequent and it’s not difficult to lose track of keys or find that the locking mechanisms aren’t working when needed.
Conclusions
Non-Instrumented IPLs have process safety roles that are every bit as important as Instrumented IPLs. However, as they are often passive design features and may be so similar to other equipment, they often fall out of view and fail due to age, neglect or modifications. It is of critical importance that these Non-Instrumented IPLs are clearly documented and that their process safety functions are clearly communicated to Operations and Maintenance personnel so they can be taken into account during Management of Change activities. A system that manages only Instrumented IPLs and does not allow management of Non-Instrumented IPLs is incomplete and can be an obstacle to effective IPL and Process Safety Management.
Rick Stanley has over 40 years’ experience in Process Control Systems and Process Safety Systems with 32 years spent at ARCO and BP in execution of major projects, corporate standards and plant operation and maintenance. Since retiring from BP in 2011, Rick has consulted with Mangan Software Solutions (MSS) on the development and use of MSS’s SLM Safety Lifecycle Management software and has performed numerous Functional Safety Assessments for both existing and new SISs.
Rick has a BS in Chemical Engineering from the University of California, Santa Barbara and is a registered Professional Control Systems Engineer in California and Colorado. Rick has served as a member and chairman of both the API Subcommittee for Pressure Relieving Systems and the API Subcommittee for Instrumentation and Control Systems.



")